TODO: faire article ! Indiquer avantages/inconvenient, type de monitoring (hard, services, processings), alert/etat courant, graphes etc...
Managing such a cluster requires some tools to raise alerts when anomalies occur (hardware failures or system issues) but also to investigate current or past state of the cluster. Here are a few tools we use at Cersat.
- Nagios

-
Munin (deprecated: pourquoi !?)
-
Ganglia
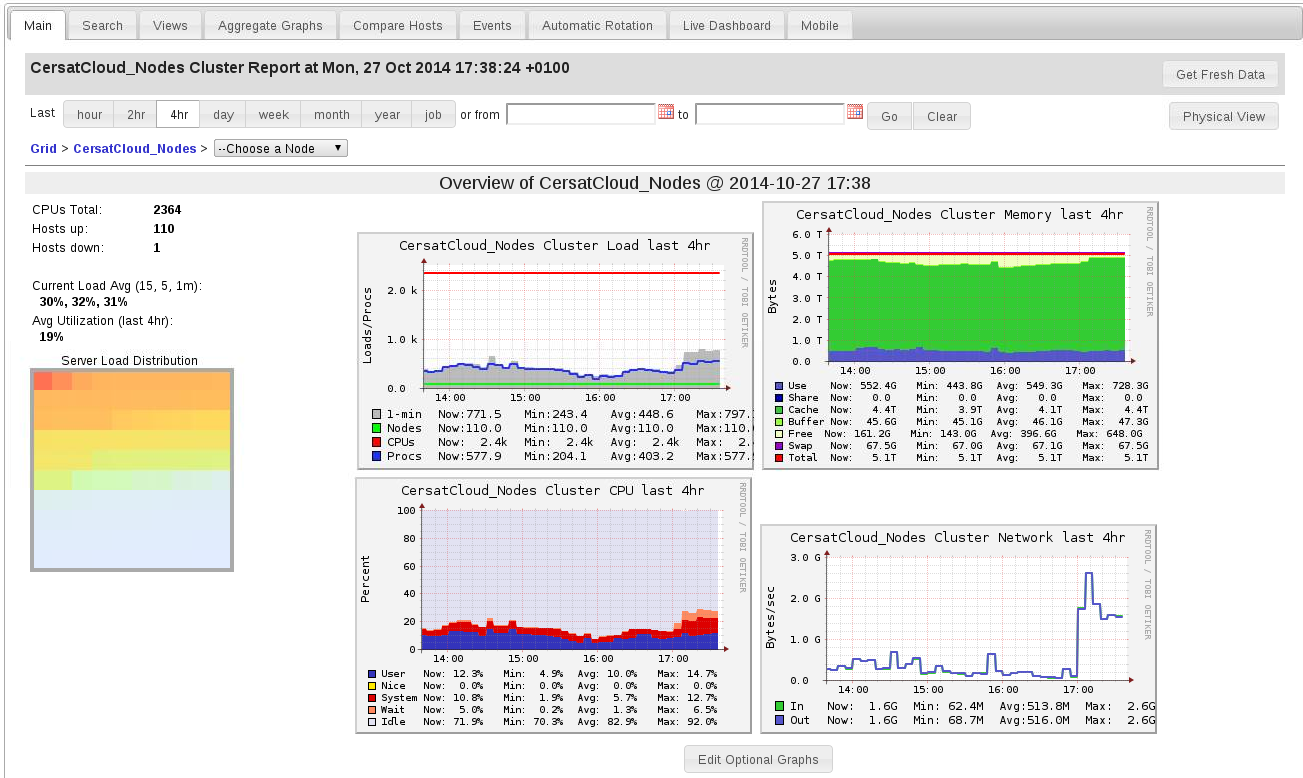
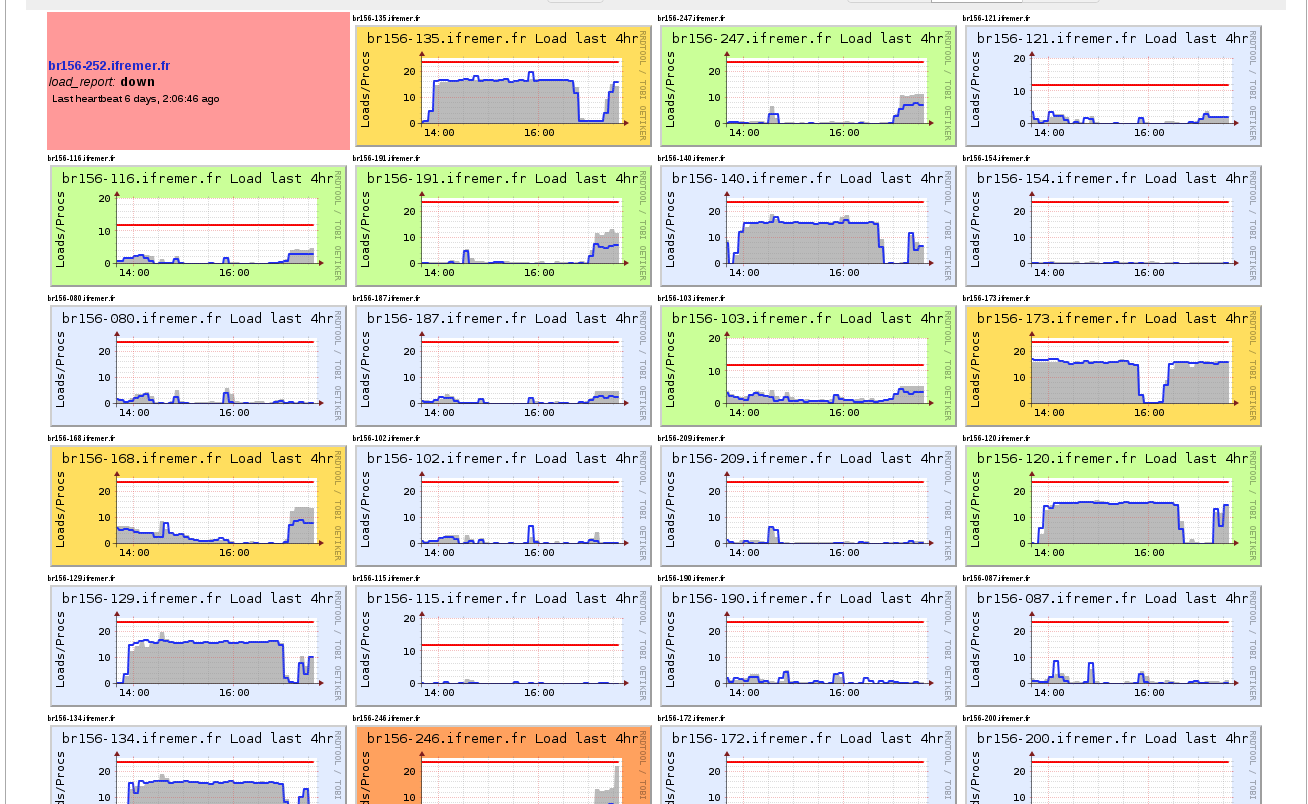
-
OpenTSDB
-
Homemade tools
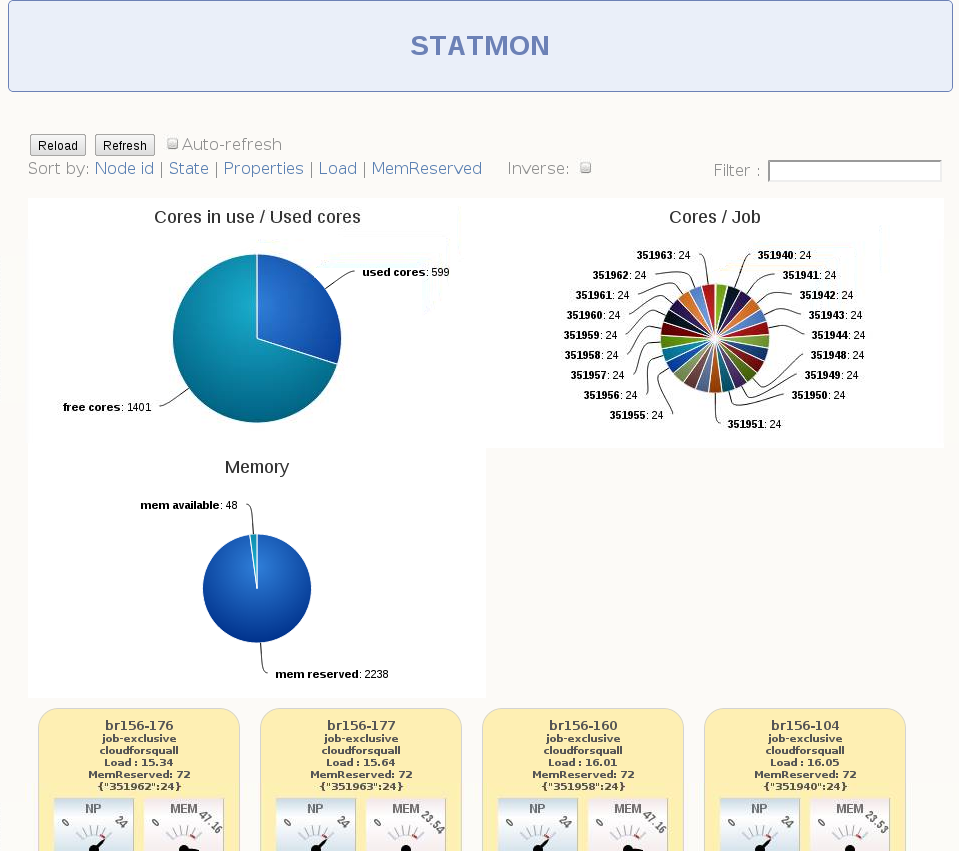
Comments
comments powered by Disqus