Datacrunch is a data crunch tool based on Hadoop processings
more ...Here is a new article about DataCrunch, following DataCrunch Introduction. We will focus on DataCrunch design and technical implementation.
This article details how we perform analytics computations on all our scientific datasets in native format (Netcdf, Hdf, ...), using terabytes of data and millions files, with only 30 lines of Python ...
more ...Datacrunch is a framework based on Hadoop which aims to make easy and fast to extract and compute meaningful informations from earth observation datasets (ie. satellite, insitu ocean buoys/drifters, models...).
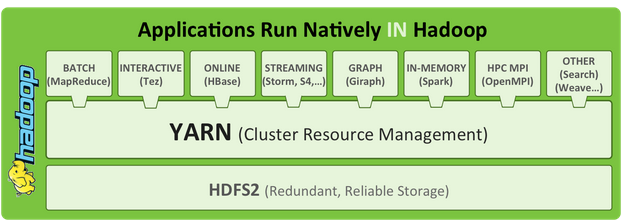
DataCrunch is a Cersat homemade framework, result of our experiments using BigData technologies, taking benefit from Map/Reduce ...
more ...At Cersat, we manage and use everyday data from dozens of satellite mission archives. This requires a big storage archive capacity since satellite datasets are nowadays about a few hundred gigabyte to hundreds of terabytes, and even petabyte for new missions.
more ...The platform software architecture relies on several layers, each containing one or more components :